|
형태소 분석 방법 (Algorithm)
'꼬꼬마 형태소 분석기'는 띄어쓰기 오류에 덜 민감한 한글 형태소 분석기이다. 기본적으로 동적 프로그래밍(Dynamic Programming)을 이용해서 모든 가능한 형태소 분석 후보를 생성하고 적합하다고 판단되는 순서대로 분석 후보들을 정렬한다. 상용 형태소 분석기에 뒤지지 않는 성능을 보이기 위해서 다양한 최적화 방법을 이용한다. 속도를 위해서는 기분석 사전을 이용한 인접 조건 검사 방식을 이용하고, 품질을 위해서는 몇가지 휴리스틱(Heuristic)과 히든 마르코프 모델(HMM: Hidden Markov Model)에 기반한 확률 모델(Probabilistic Model)을 이용한다. 1) 동적 프로그래밍(Dynamic Programming)
어절을 기본 단위로 하는 형태소 분석 알고리즘에서는 후순위 최장 일치법과 같은 방법을 이용해서 어절의 뒷부분부터 형태소를 분석하는 것으로 성능을 크게 높일 수 있다. 그러나 띄어쓰기 오류가 포함되었을 때에는 어디에서 띄어쓰기가 잘 못 됐는지 확인을 해야하며, 극단적으로 띄어쓰기가 전혀 되어 있지 않아서 매우 긴 어절이 입력이 되는 것과 같은 경우에는 이같은 방법을 이용하기 어렵다. 따라서, 어절의 앞부터 띄어쓰기 오류에 대한 가능성을 고려하면서 모든 가능한 형태소 조합들을 생성해 나가야 한다. 만약 음절을 기준으로 한다면, 각각의 음절을 기준으로 형태소를 생성하는 과정이 된다. 아래 그림과 같이 'abcdefgh'라는 어절이 있다면, 이는 각 어절의 사이 'qrstuvw'를 기준으로 형태소가 구분될지 않될지를 확인하는 과정이 된다.
┌─┬─┬─┬─┬─┬─┬─┬─┐
│a│b│c│d│e│f│g│h│ └┬┴┬┴┬┴┬┴┬┴┬┴┬┴┬┘ │q│r│s│t│u│v│w│ └─┴─┴─┴─┴─┴─┴─┘ [그림 1] 형태소 분석 문제
예를 들어 r과 t 위치에서 형태소가 구분된다면, 위의 어절은 ab, cd, efgh라는 세개의 형태소로 이루어진 어절이 된다. 따라서 n개의 음절이 주어졌다면, n-1개의 음절 사이위치가 형태소 구분위치인지 아닌지에 대한 문제가 되며, 그 복잡도는 O(2n-1)이 된다. 일반적으로 한글이 한 어절을 이루는 음절 수가 5개를 넘어가는 경우가 많지 않다고 하면, 24 = 16으로 그리 복잡하지 않지만, 실제로 하나의 음절에서 하나 이상의 가능한 형태소가 나온다는 것을 감안한다며, 더욱 많은 조합이 발생할 수 있다. 또한 띄어쓰기 오류로 인해, 한 어절의 음절이 길어진다면 이는 더욱 복잡한 문제가 된다. 따라서 이를 해결하기 위해 일정량의 메모리를 사용하여, 순차적으로 최적 결과를 갱신하는 동적 프로그래밍을 사용한다. 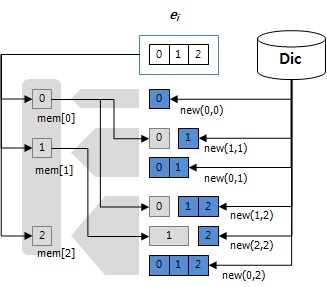
[그림 2] 동적 프로그래밍을 이용한 형태소 분석
[그림 2]에서 보이는 바와 같이 어절의 길이를 늘려 가면서 해당 길이에서 가능한 형태소 분석 조합들을 생성하여 메모리에 저장한다. 그리고 길이를 순차적으로 늘려가면서 기존에 저장되어 있는 결과를 이용해서 새로이 생성되는 결과를 만들어 낸다. 예를 들어 길이 5인 어절에 대한 분석을 수행할 때에는 1~4길이에서 나올 수 있는 형태소 분석 조합을 모두 생성되어 있기 때문에, 다음과 같은 조합에 대해서만 생성하면 된다.
2) 기분석 사전을 이용한 인접 조건 검사에 의한 형태소 분석
꼬꼬마 형태소 분석기는 [6]에서 제시한 '부분 어절에 대한 기분석 사전을 이용한 인접 조건 검사에 의한 형태소 분석 방법'을 이용한다. 음절 단위로 기분석 된 형태소를 1) 에서 설명한 동적 프로그래밍 방법으로 사전을 조회하면서 순차적으로 확장해 나가는데, 형태소가 결합될 수 있는지의 여부를 결합 조건을 이용해서 확인한다. 결합조건의 유형으로는 a) 품사 결합 조건, b) 음운 결합 조건, c) 형태 결합 조건가 있다.
a) 품사 결합 조건
품사 결합 조건은 한 어절에서 결합할 수 있는 형태소 품사들을 말하는 것으로 후위 형태소 앞에 올 수 있는 전위 형태소를 한정함으로써,
형태소 조합이 올바른 것인지를 확인한다. 예를 들어 어미 앞에는 용언(선어말 어미 포함)의 어간만이 올 수 있다. 또한, 조사 앞에는 체언이 와야 한다.
이같은 품사 제약 조건을 명시함으로써 불가능한 형태소 조합을 배제한다.
b) 음운 결합 조건
형태소가 결합할 때 특정한 음운 조건을 만족해야하는 경우가 있다. 예를 들어 조사 '를'은 앞에 오는 형태소의 마지막 음절이 종성을 포함해야 한다. 또한
c) 형태 결합 조건
꼬꼬마 형태소 분석기는 음절을 기준으로 형태소 분석을 수행하기 때문에 어미 'ㅂ니다', 'ㄴ인지'와 같이 음소 단위로 형태소가 이루어지는 경우에 대한
형태소 분석이 불가능해 진다. [6]에서는 이를 해결하기 위해서 실질적으로 음절 단위로 형태소를 구분하고, 나중에 음소 단위의 형태소가 복원될 수 있도록 하였다.
예를 들어 형태소 'ㅂ니다'와 같은 경우 '받침이 없는 용언의 어간'과 결합할 수 있는데, 이같은 받침이 없는 용언의 어간에 'ㅂ'을 결한한 형태를 미리 생성하고,
'ㅂ'이 결합되었다고 조건을 명시한다. 그리고 'ㅂ니다'는 '니다'로 형태를 바꾸고, 'ㅂ'이 결합한 용언의 어간과만 결합할 수 있다는 제약 조건을 준다.
이같이 하면 실제로 결합 시 '니다'는 실질적으로는 'ㅂ니다'라는 형태소로 복원되고, 음절 단위로 형태소 조합을 생성해 낼 수 있다.
조건 인코딩
형태소는 인접한 형태소에 의해서만 그 조합의 실제 출현 가능 여부가 결정된다.
따라서 기분석 후보간의 조합 가능 여부를 확인할 때에는 전위 기분석 후보의 마지막 형태소와 후위 기분석 후보의 첫번째 형태소에 의해서만 두 조합의 결합 가능성을 확인하면 된다.
후위 기분석 후보에서 전위 기분석 후보와 결합 가능한지를 확인하는데, 후위 기분석 후보는 결합 가능 품사를 OR조건으로 만족하는지 확인하고,
음운 결합 조건과 형태 결합 조건은 AND조건으로 결합 여부를 확인한다. 기분석 사전 구조
꼬꼬마에서는 규칙 기반으로 선호되는 형태소 조합을 찾기 위해서 세가지 조건에 4) 결합 선호 조건을 추가하였다. 최종적으로, 부분 어절 기분석 사전은 아래와 같이 표층어와 이에 대한 기분석 결과 및 결합 조건 정보를 가지고 있다.
표층어:{[형태소/tag+형태소/tag+...]#(tags)&(conds)@(conds)~(conds)¬(conds)%(conds)}
여기서 ~(conds), ¬(conds), %(conds)는 꼬꼬마에서 추가된 것으로, 형태소의 결합 조건을 좀더 명확히 나타내기 위해서 추가하였다. 예를 들어 '끝음절이'ㄹ'이 아닌 받침을 가진'과 같은 조건을 나타내기 위해서는 @(자음)¬(ㄹ)로 나타낸다. 이는 [6]에서 제시한 방법으로는 표시할 수 없다. 또한 ~(conds)는 전위 분석 후보가 특정한 후위 후보와만 결합할 수 있음을 확인하는 것으로 전위 후보가 후위 후보 결합을 제한하도록 하기 위함이다. 예를 들어 'ㅅ'탈락 으로 활용된 용언의 어간은 후위 후보의 어미의 첫음절이 초성이 없는 즉 초성이 'ㅇ'인 경우에만 결합할 수 있다. 이같은 조건들은 사전에 각 기분석 후보가 적재되면서 자동으로 초기화 된다. 각 결합 조건에 대한 상세한 내요은 결합 조건 표를 통해 확인할 수 있다. 3) 확률 모델을 이용한 최적 분석 후보 선정
꼬꼬마에서는 위와 같은 배제 조건을 이용한 형태소 분석후보 생성 방법뿐만 아니라, 생성된 분석 후보중에서 더 가능성이 높은 분석 후보를 확률 모델(Probabilistic Model)을 이용해서 선택한다. 본 확률 모델은 띄어쓰기 오류와 형태소 분석 호부 선택을 동시에 최적화 하는 분석 후보를 찾는 것으로 기존의 방법들보다 발전된 것이다. 자세한 모델은 파일을 통해서 확인할 수 있다. 4) 성능 개선을 위한 프로그램 최적화 (Program Tuning)
동적 프로그래밍을 이용한다고 해도, 분석 후보의 수는 줄어들지 않기 때문에 분석 후보의 수를 적당한 순으로 유지하면서 최종 후보로 확장해 나가야 한다. 이를 위해 어느정도 길이 이상의 어절에 대해서는 도중에 부적합할 것이라고 여겨지는 분석 후보에 대한 가지치기 (Pruning)을 수행하면서 성능 개선을 시도하였다. will be updated... 아래 그림은 1), 2), 3), 4)를 포함하는 과정을 수행하는 프로그램 흐름을 모식도로 보여준다. 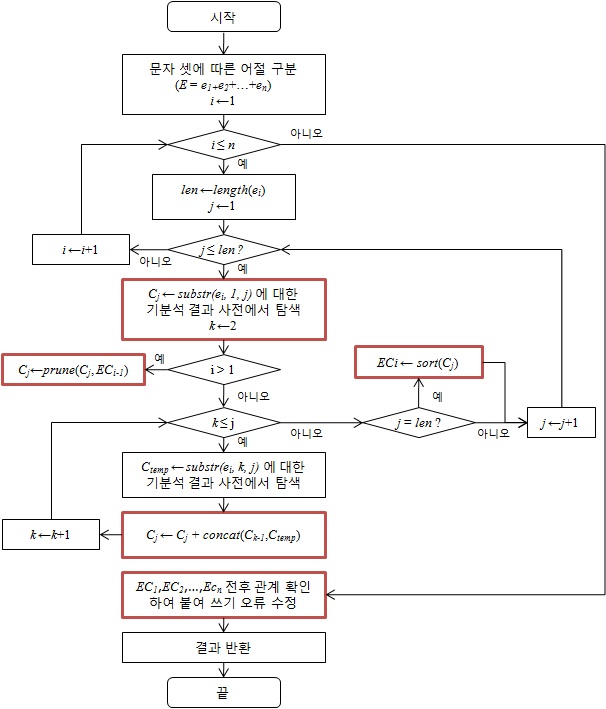
[그림 3] 프로그램 흐름도
References
|
꼬꼬마 세종 말뭉치 활용 시스템은 현재 세종 말뭉치 2010년 배포판을 이용하고 있습니다.